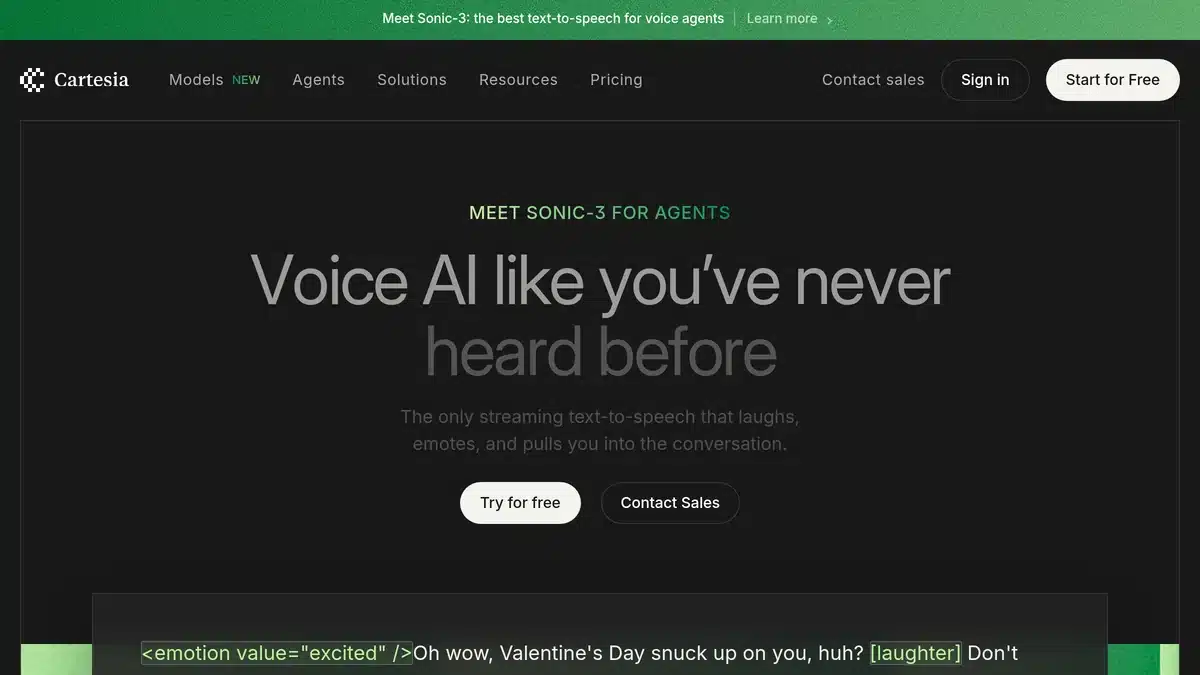
الخط الفاصل بين “الطبيعي” و”الاصطناعي” في عالم الصوت تلاشى تماماً مع نموذج Cartesia Sonic-3 🔥🎙️
أطلقت شركة Cartesia نموذجها الأيقوني Sonic-3، وهو القفزة الأكبر التي شهدناها في تقنيات تحويل النص إلى كلام (TTS) !!
بتمويل ضخم بلغ 100 مليون دولار، استطاع هذا النموذج أن يغير قواعد اللعبة بالكامل عبر محاكاة أنماط التنفس، والترددات العاطفية، وحتى “رنين الصوت” البشري بدقة مذهلة تجعلك لا تفرق بين الآلة والإنسان ؛؛
✴️ يعتمد النموذج على هندسة State-Space Models (SSMs)، وهي تقنية متطورة تمنحه كفاءة وسرعة فائقة مقارنة بالنماذج التقليدية، وبزمن استجابة لا يتجاوز 90 مللي ثانية فقط.
✴️ ليس مجرد “قارئ نصوص”، بل أصبح Sonic-3 يلتقط أدق التفاصيل البشرية (Micro-patterns) مثل التنهيدات البسيطة، والتردد في الكلام، وحتى النبرات الصوتية المجهدة (Vocal fry)، وبالتالي تحصل على تجربة سمعية بشرية بامتياز لا يمكن تفرقتها عن الواقع.
✴️ يدعم النموذج 42 لغة – منها العربية مع بعض الضعف – بمدى عاطفي كامل، ويتيح إنتاج حلقات بودكاست كاملة أو رواية كتب صوتية في دقائق معدودة.
👋 الفرق برأيي بين أن نكون أمام “روبوت يتكلم” وبين “آلة تبدو حية” يكمن في هذه التفاصيل الصوتية الصغيرة التي نجحت Sonic-3 في فك شفرتها.
الرابط 🔗








 سوريا
سوريا
 مصر
مصر
 الإمارات
الإمارات
 السعودية
السعودية
 قطر
قطر



