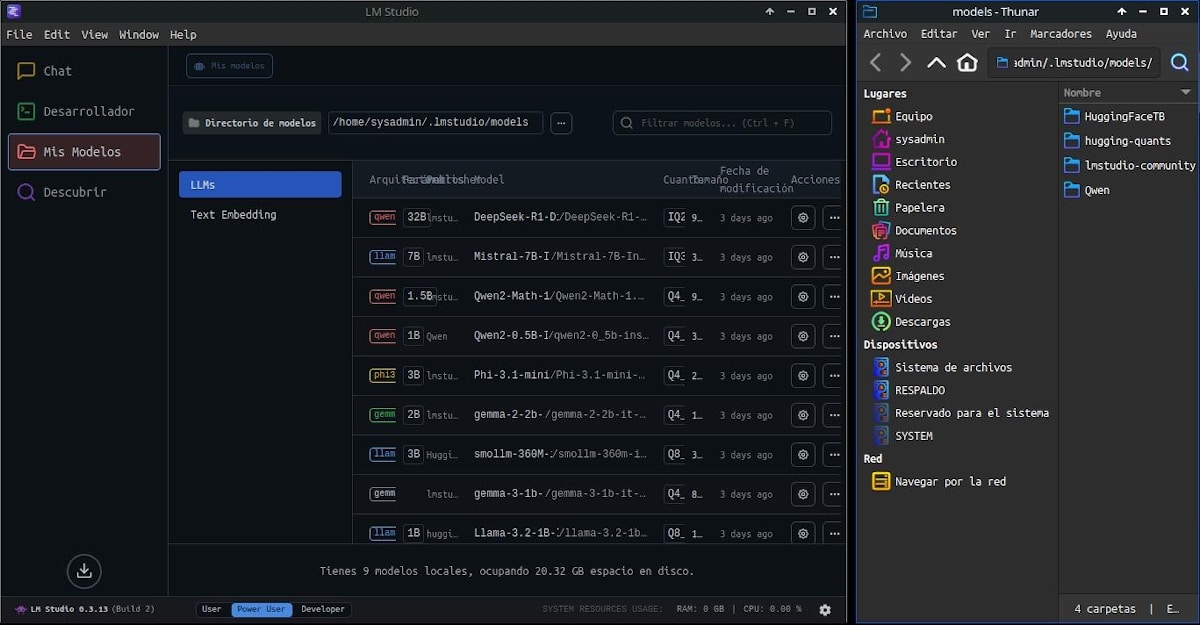
من bin. إلى GGUF: عندما يصبح تشغيل الـ LLM على الأجهزة الطرفية المحدودة (Edge) ممكنًا
كانت تخزن النماذج سابقًا بصيغة .bin أو .pt باستخدام torch.save() لكنها عانت من مشكلة أمان خطيرة؛
ثم جاءت Safetensors لتحسين الأمان، لكنها بقيت ثقيلة على المعالجات .. !!
أصبحت GGUF (المستخدمة مع GGML) اليوم مغير حقيقي لقواعد اللعبة:
✴️ تنسيق ثنائي لنماذج مُكممة (quantized).
✴️ تحميل وتنفيذ أسرع.
✴️ متوافقة مع llama.cpp – Ollama – LMStudio – vLLM
تعمل GGUF وفق ثلاثة أنماط تكميم رئيسية:
~ Legacy Quants :: سريعة لكنها محدودة الدقة
~ K-Quants :: توازن بين الأداء والحجم
~ I-Quants :: ذكية تحدد الأوزان الأهم بدقة
👋 نجحت Unsloth في ضخ العديد من نماذج GGUF على منصة Huggingface وهو إسهام يحسب لهم ؛؛
تعتمد معظم نماذج GGUF اليوم على K وI-Quants لتحقيق أداء قوي واستهلاك منخفض للذاكرة؛ وهو ما يجعل GGUF الخيار المثالي لتشغيل LLMs على الأجهزة محدودة الموارد 🔥








 سوريا
سوريا
 مصر
مصر
 الإمارات
الإمارات
 السعودية
السعودية
 قطر
قطر



