ماذا لو كان بمقدور الـ LLM إخبارك أثناء التوليد أنه سيولد استجابة غير دقيقة (هلوسة) 🔥🤯
أطلق فريق من الباحثين (بقيادة أسماء لامعة مثل Sergey Levine وRohin Manvi) ورقة بحثية استوقفتني الليلة للمطالعة، تقدم منهجية ZIP-RC !!
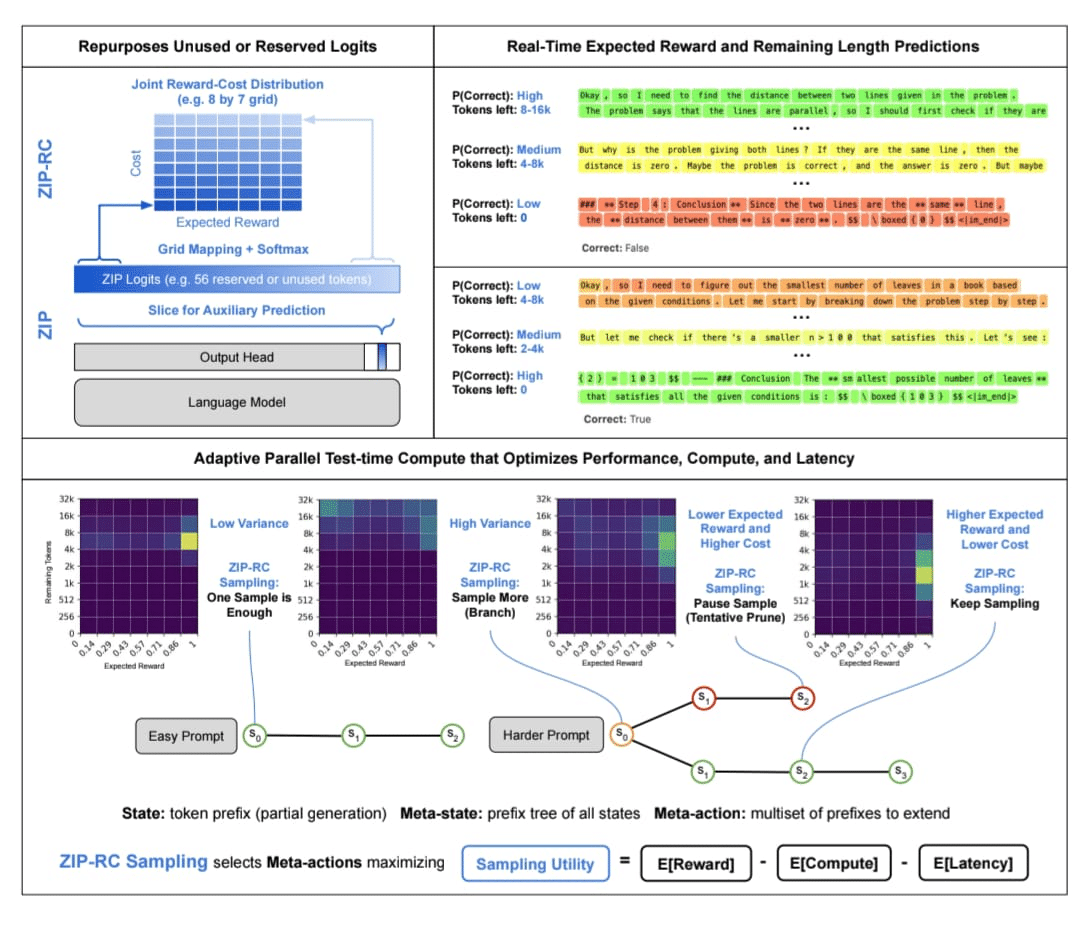
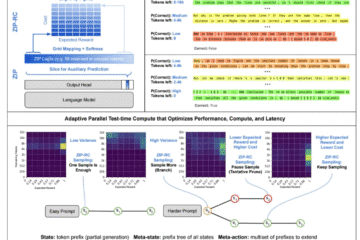
تمنح هذه التقنية النماذج اللغوية الضخمة (LLMs) قدرة على “الاستبطان اللحظي” (Real-time Introspection) دون أي زيادة في التكاليف الحسابية أو تغيير في معمارية النموذج ؛؛
✴️ تكمن العبقرية التقنية في ZIP-RC في إعادة توظيف قيم (Logits) غير المستخدمة للتنبؤ بالتوزيع المشترك لـ reward وطول النص المتبقي عند كل “Token” يتم توليده، وهو ما يمنحنا رؤية داخلية لما يدور في “عقل” الآلة دون أي حمل إضافي على المعالج.
إليك أهم ما يجعل هذه المنهجية تحول لافت في كفاءة الاستدلال (Inference Efficiency) ::
✴️ القضاء على هدر الموارد في تقنيات (Best-of-N sampling) التقليدية؛ حيث يقوم ZIP-RC بحساب sampling utility بدقة لموازنة الـ reward المتوقعة مع زمن الاستجابة، وبالتالي يتم تخصيص جهد حسابي أكبر للمسائل المعقدة وجهد أقل للمسائل البديهية، ما يرفع الدقة بنسبة 12% في اختبارات الرياضيات المختلطة.
✴️ إن مجرد وجود درجة ثقة لا يخبرك إذا كان المسار يستحق الاستكمال أم لا، بينما يتيح التوزيع المشترك لـ ZIP-RC تقييم reward-cost لكل عينة إضافية، وهو ما يجعل عملية التفكير أكثر عقلانية واقتصادية.
✴️ تم صقل المنهجية باستخدام 100 ألف عملية توليد من نماذج متطورة مثل DeepScaleR وبيانات MATH و GSM8K، وأثبتت نجاحاً مذهلاً في اختبارات AMC و AIME من خلال مطابقة توقعات النموذج للنتائج الواقعية.
الرابط 🔗









 سوريا
سوريا
 مصر
مصر
 الإمارات
الإمارات
 السعودية
السعودية
 قطر
قطر



