تجربتي مع كتاب Build a Reasoning Model: تحسين دقة النماذج لا تحتاج دائما إلى إعادة تدريبها
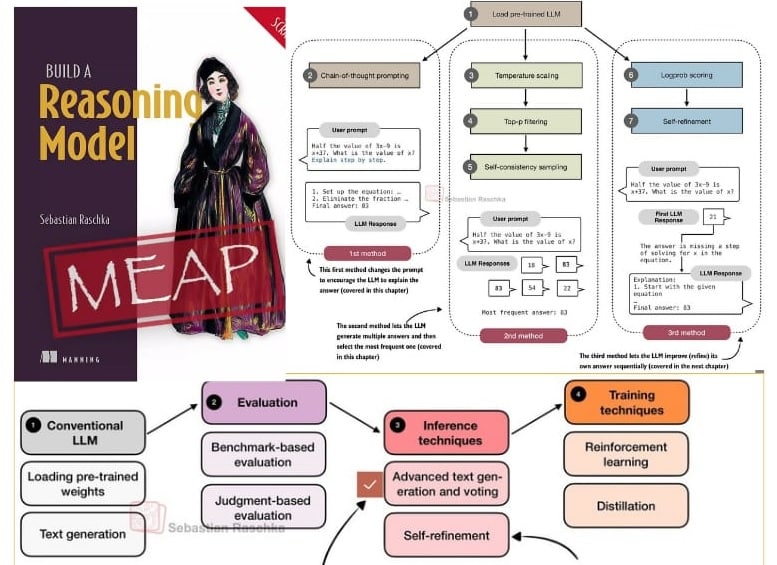
ناقش فصل من كتاب “بناء نموذج استدلال” أن الـ Inference-scaling (توسيع الحوسبة وقت الاستدلال) أصبح أداة مركزية تُتيح لنا مبادلة مزيدٍ من القدرة الحاسوبية مقابل قفزات ملموسة في دقة النماذج؛ دون الحاجة إلى إعادة تدريب النموذج !!
يشرح الفصل (35 صفحة) طريقة الـ self-consistency sampling – تعتمد على دفع النموذج إلى حل السؤال أكثر من مرة ثم اختيار أفضل إجابة من المحاولات – والتي أظهرت كيف ارتفعت دقة نموذج الأساس على معيار MATH-500 من 15.2% إلى 52.2% (باستخدام هذه الاستراتيجية فقط. )
أبرز النقاط العملية في الفصل التي قد تهم مهندسي الـ ML 👇
✴️ تجربة مفهوم الاستدلال متعدد المسارات (sampling of reasoning paths) والاعتماد على تصويت الأغلبية لانتقاء الإجابة الأكثر اتساقًا.
✴️ تكلفة حسابية قابلة للقياس لحساب كيف نختار N عينات (Best-of-N / Self-Consistency / OptScale) لتحقيق توازن بين الدقة والمقدرات الحاسوبية.
✴️ ربط هذا كله لاحقا مع تقنيات مثل self-refinement، حيث يحسن النموذج إجاباته عبر جولات منهجية من التفكير المتكرر.
ما زلت في حقل تجارب الكتاب ولكن باختصار 👋 تعد هذه الأساليب من أسرع الطرق لرفع الأداء على مهام التفكير الحسابي والمنطقي في حال ((توافرت موارد زمنية أو حاسوبية كافية؛))، وهو ما يجعلها مفيدة للباحثين والمهندسين الذين يعملون على منتجات تحتاج دقة عالية دون بنى تدريبية مكلفة !!!
مصدر الكود والمواد 🔗
https://github.com/rasbt/reasoning-from-scratch/blob/main/ch04/01_main-chapter-code/ch04_main.ipynb








 سوريا
سوريا
 مصر
مصر
 الإمارات
الإمارات
 السعودية
السعودية
 قطر
قطر



