الفريق الذي بنى نماذج Qwen: يطلق دليل عملي شامل للنماذج البصرية (VLM Cookbook)
يمثل (Qwen VLM Cookbook) دليلاً عملياً لا غنى عنه للمطورين والباحثين في مجال الذكاء الاصطناعي متعدد الوسائط !!
✴️ صُمم هذا الدليل لتبسيط استخدام نموذجهم المتقدم Qwen3-VL – أحد أقوى النماذج البصرية اللغوية المفتوحة المصدر المتاحة حتى الآن – حيث يضع قدرات النموذج الهائلة في متناول الجميع لتنفيذ مهام الرؤية المعقدة.
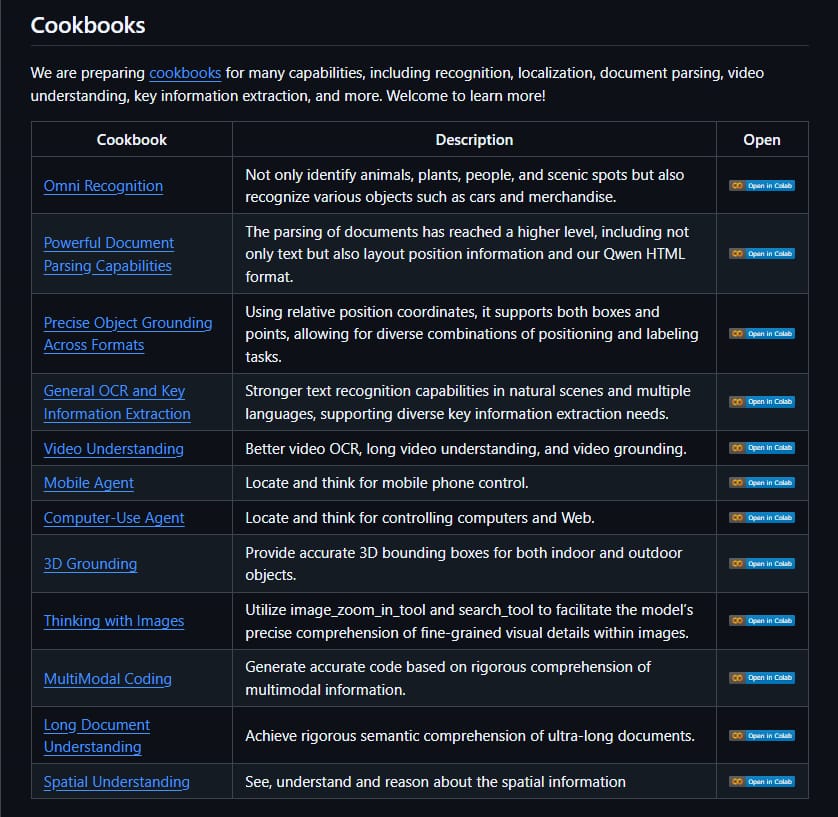
قدرات نموذج Qwen3-VL ومهام الـ “Cookbook” 👇
✴️ يُغطي (VLM Cookbook) مجموعة واسعة من سيناريوهات العمل الفعلية، ويُظهر براعة Qwen3-VL في التعامل مع التحديات التي تتطلب فهماً عميقاً للنص والصورة معاً؛ وتشمل المهام المدعومة ما يلي:
✴️ التعرف البصري الشامل (Omni Recognition) :: حيث لا يقتصر على تحديد الكائنات المألوفة، بل يتعرف على المنتجات والكائنات في المشاهد المعقدة.
✴️ توطين الكائنات بدقة (Object Grounding) ::
يوفر إحداثيات موضع دقيقة للكائنات المطلوبة داخل الصورة، وهو ما يُعد حاسماً في تطبيقات الواقع المعزز والروبوتات.
✴️ تحليل المستندات المعقدة (Document Parsing) ::
حيث يتجاوز مجرد التعرف على الحروف (OCR) إلى فهم بنية المستندات الطويلة واستخراج المعلومات الرئيسية منها بأكثر من 32 لغة.
💡 يُعدّ دليلاً جديداً على ريادة مجموعة علي بابا في تقديم حلول الذكاء الاصطناعي مفتوحة المصدر ذات الأداء العالمي، ويُعزز من قدرة المطورين على بناء جيل جديد من الوكلاء البصريين !!!
معلومة :: يُعد Qwen3-VL-235B-A22B إصداراً من طراز MoE (مزيج الخبراء)، ما يسمح بتفعيل 22 مليار مُعامل فقط من أصل 235 مليار معاملاً في المجمل لكل خطوة تنفيذ؛ وبالتالي يوازن بين الكفاءة الهائلة في القدرات ومتطلبات الحوسبة.
اطلع على الـ Cookbook واستكشف الأمثلة 🔗👇








 سوريا
سوريا
 مصر
مصر
 الإمارات
الإمارات
 السعودية
السعودية
 قطر
قطر



