
أسبوع الـ OCR بامتياز : ثلاثة نماذج تتصدر الموجة
يغزو فيضان من نماذج التعرف البصري (OCR) منصة Hugging Face مؤخراً، ويؤكد هذا التدفق على أن نماذج اللغة البصرية (VLMs) أصبحت هي المهيمنة على معالجة المستندات المعقدة؛ حيث تتصدر ثلاثة نماذج توجهات الأداء والكفاءة وهي ::
✴️ DeepSeek-OCR
- أصدرته DeepSeek.
- يركز على تقنية الخريطة البصرية ثنائية الأبعاد (Optical 2D Mapping)، لتقليل الرموز البصرية المستخدمة لكل صفحة بنسبة 90%، وهو ما يترجم إلى معالجة أكثر من 200 ألف صفحة يومياً بوحدة معالجة رسوميات واحدة (GPU).
- يتفوق النموذج على نماذج قوية مثل GOT-OCR 2.0 وMinerU 2.0 مع استخدامه لنحو 100 رمز بصري فقط بدلاً من 256 أو أكثر.
✴️ PaddleOCR-VL
- نموذج من Baidu.
- مصمم خصيصاً لتحليل المستندات.
- يدمج مُشفّراً بصرياً بأسلوب NaViT لمعالجة الصور بدقة أصلية (دون تصغير أو تشويه) مع نموذج اللغة ERNIE 4.5، وهو ما يحقق نتائج رائدة في مقياس OmniDocBench لتحليل المستندات.
- يدعم النموذج 109 لغات.
✴️ Nanonets-OCR2
- نموذج من Nanonets.
- يعمل على تحويل المستندات إلى صيغة Markdown مُهيكلة.
- يتميز بالقدرة على التعرف الذكي على المحتوى المعقد؛ مثل: المعادلات بـ LaTeX والجداول المعقدة وصناديق الاختيار وحتى المخططات، ويجعل هذا التحويل النموذج مثالياً لمراحل المعالجة اللاحقة بواسطة نماذج اللغة الكبيرة (LLMs).
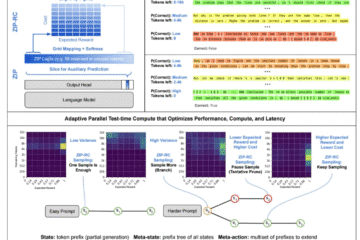
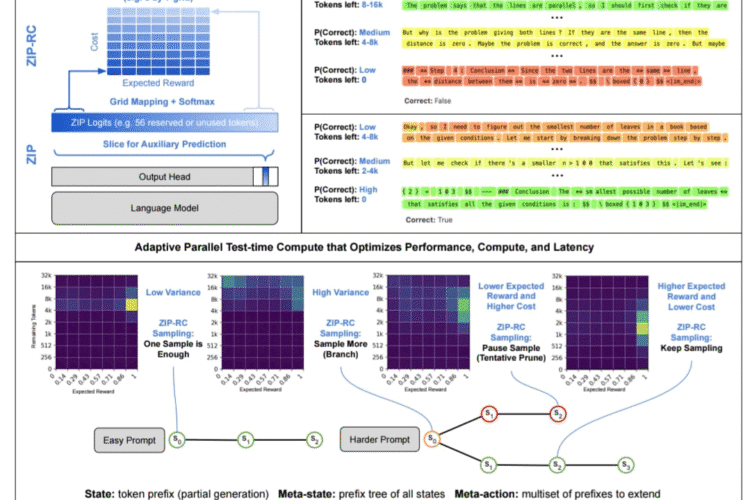
💡 يشير هذا التحول بوضوح إلى أن دمج الفهم البصري العميق مع كفاءة الرموز يفتح آفاقاً جديدة لأتمتة معالجة الوثائق على نطاق واسع.
DeepSeek-OCR على Hugging Face 🔗
https://huggingface.co/deepseek-ai/DeepSeek-OCR
PaddleOCR-VL Demo 🔗
https://huggingface.co/spaces/PaddlePaddle/PaddleOCR-VL_Online_Demo
Nanonets-OCR2 🔗








 سوريا
سوريا
 مصر
مصر
 الإمارات
الإمارات
 السعودية
السعودية
 قطر
قطر



